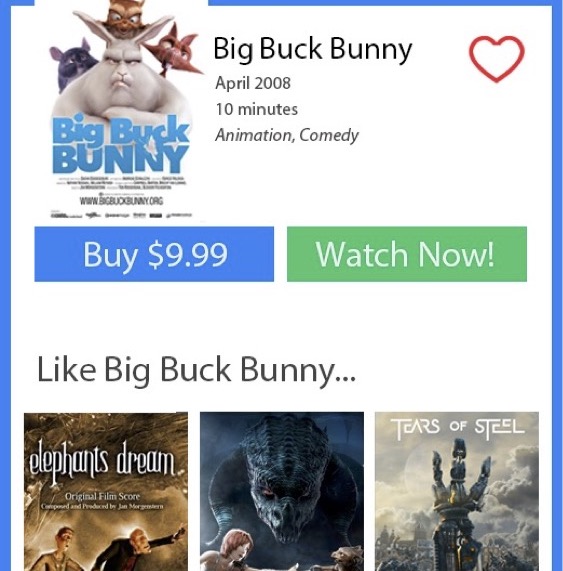
We’ve all seen this: you select an item online, and at the bottom you are recommended items that are “More Like This”, “Similar to this” or “Users who liked this also liked…”. But are these items actually similar?
A survey of major platforms at the time showed that Similar items were not always similar. In one platform when the movie Titanic was selected, similar movies recommended included Iron Man, Thor, and Ninja Turtles. While assessment of similarity might be subjective, it is hard to imagine how one of the greatest love tragedies of a generation could be similar to a movie of pizza-eating, sewer-dwelling reptiles.
I hypothesized that a major reason why this happened was the lack of ground truth, or data representing which movies people thought were similar. Lacking this data, machine learning professionals fell back onto unsupervised learning methods, and/or methods that were built to prioritise what they thought made movies similar.
This is counter to how experiences are built and improved.
So I set out to collect data. But there was no way I could do all of this alone, so I recruited students from instead. I chunked the work into smaller parts achievable by a team of 3-5 and pitched it to Carnegie Mellon University, trained the students in the necessary skills including information retrieval, machine learning, statistical analysis, and web design and we were off.
We built a crowdsourcing platform where people could informs what movies they thought were similar. We then used this data to build supervised learning models, and we ran quantitative tests to validate that supervised learning methods were in fact superior.
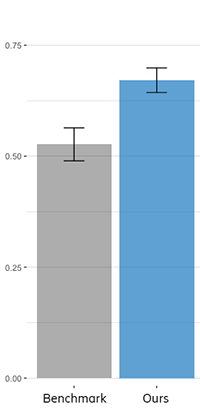
We ran this study multiple times and with different setup, and it came back the same every time: if we have data from users, even just a little bit of data, it improved the results. We managed to translate similarity from an unsupervised learning problem into a supervised learning problem, and this made all the difference.
What’s more, with this new supervised model we could do other types of recommendations. We could address the so-called “cold start problem”, where new items were not recommended enough, or new users did not receive good recommendations.
Impact
This work was included in our media product to improve “More Like This” recommendations. It took approximately 18 months between my hypothesis and productisation.
We also discussed with the owners of media metadata on how they can create a new solution for existing customers and with existing data, if they allowed their army of content curators to submit perceived similarity judgements.
This was my first major project at Ericsson, and it allowed me to position myself as an advocate for human factors, introduced us all to the concept of human-centred machine learning, and promoted usability throughout Ericsson Research.
Role
This project started in 2015 and ran through 2017 (until the company divested from the media business). Throughout this project I served as the Primary Investigator. I supervised 3 groups of students consisting of 5 members per group, and separately 3 interns, to build the platform to crowdsource similarity judgements, perform user studies, analyse data, and implement machine learning models. I also spoke to stakeholders and product owners as needed to ensure relevance and impact, as well as to propose new offerings and strategies.
Publications
This work resulted in three academic publications:
- Evaluating item-item similarity algorithms for movies
- Content-Based Top-N Recommendations with Perceived Similarity
- Finding Similar Movies: Dataset, Tools, and Methods
Two patents have been granted:
- System And Method For Recommending Semantically Similar Items
- Expert-Assisted Online-Learning For Media Similarity
And one Blogpost published: What makes movies similar?
The dataset collected has also been released and can be found at moviesim.org